Introduction¶
Overview¶
In the HERD offline software, many data processing steps often follow certain fixed patterns or rely on some common functionalities, such as:
Event loop control: In the offline data processing process, the processing of an event usually follows the sequence of data input (from network, file, or generated by physical sub-input), executing data processing algorithms, and data output, and loops through all events. In addition to sequential execution, there may also be event filtering, event nested loops, and jump processes in some special data processing processes. For parallel running mode, thread pool management, thread distribution, scheduling, and recycling functionalities are also required.
Algorithm scheduling and common service management: Algorithms refer to the processing flow applied to data, while common services encapsulate functionalities that can be shared among various data processing processes, such as data input/output and database operations. In the software development process, developers often independently develop algorithms and services, and dynamically select which algorithms to execute and which services to call during program runtime. This requires defining unified interfaces for data processing algorithms, common services, and tools, and scheduling various modules as needed during runtime.
User configuration: Before running the data processing software, users can configure runtime parameters through scripting languages or text files without the need for recompilation.
When designing offline software, these fixed patterns can be independently implemented in a reusable and extensible software, incorporating common functionalities and features in data processing to form a data processing software framework. Developers of offline software can use the framework as a foundation to develop specific data processing applications by replacing and expanding modules through various methods. Currently, there are many mature frameworks in the field of high-energy experiments, such as Gaudi, basf2, and FairRoot.
SNiPER components¶
Considering the characteristics of the HERD experiment, such as the long running time, large data volume, and high precision requirements, we have chosen SNiPER (Software for Non-collider Physics Experiment) as the underlying software framework. SNiPER is a framework software developed by IHEP and SDU, specifically designed for high-energy physics experiments. It has the characteristics of lightweight, strong flexibility, and high performance. SNiPER adopts a modular design, with modules designed with high cohesion and low coupling, communicating with each other only through standard interfaces, and each functional module can be dynamically configured and loaded at runtime.
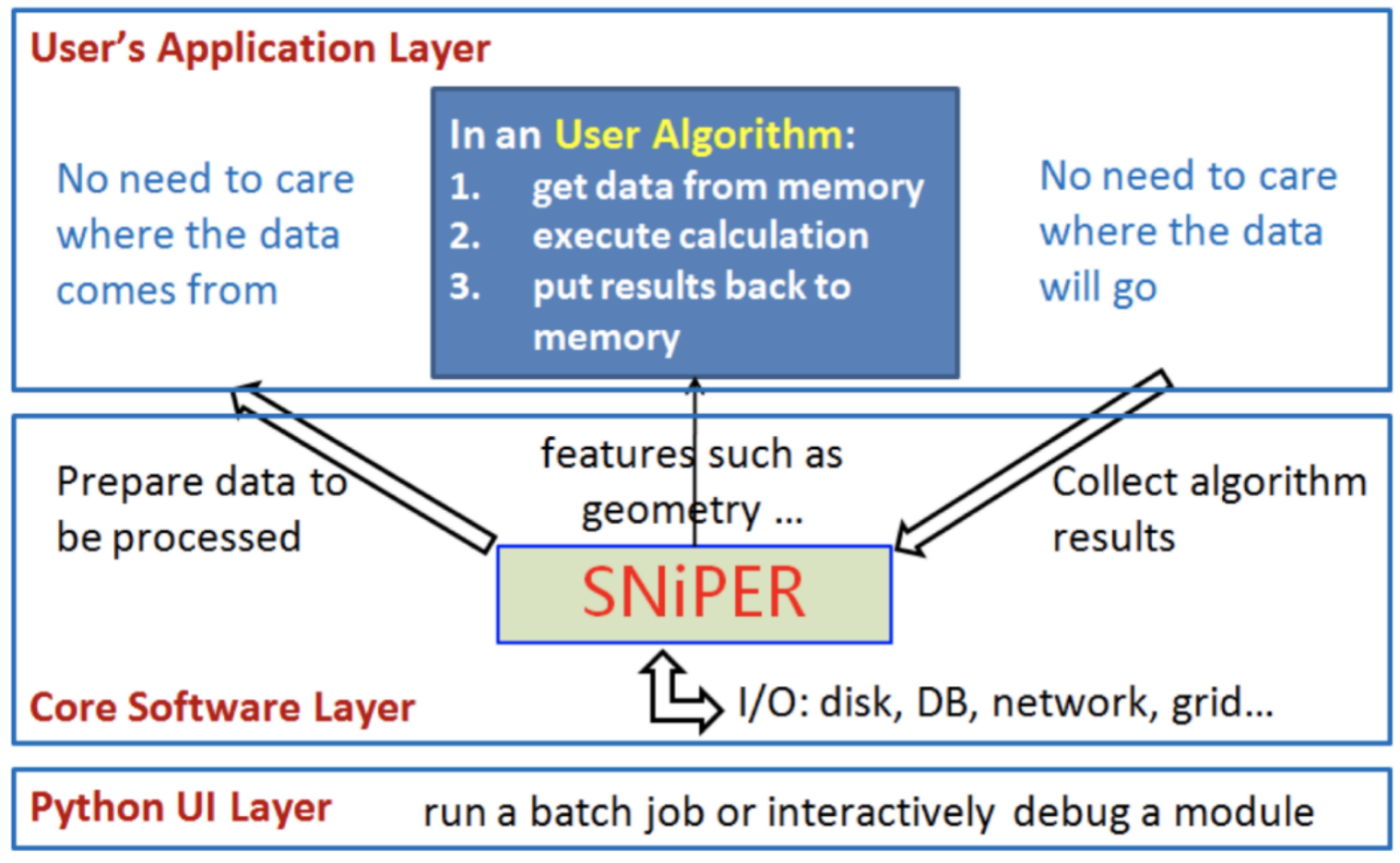
The following figure shows the overall architecture design of SNiPER, which can be divided into three levels:
User application layer: Developers develop application algorithms (such as detector simulation, reconstruction, etc.) for offline data processing using the AlgBase base class provided by SNiPER. User algorithms only focus on specific algorithm implementations, while data management and other services are implemented by the framework.
Core software layer: Based on the SvcBase and ToolBase base classes provided by SNiPER, common services such as geometry data and event data are implemented to support the user application layer.
User interface: Based on Python binding technology, a mixed programming of C++ and Python is implemented to provide a user interface based on Python.